I am currently in a very neat class on algebraic methods in combinatorics and my professor said that the very famous theorem Erdos-Ko-Rado in extremal combinatorics could be solved with linear algebra, so I decided to go ahead and try it out:
Theorem: If  such and
such and  is a collection of sets such that the sizes of every set are equal to
is a collection of sets such that the sizes of every set are equal to  and any two sets intersect, then we have that
and any two sets intersect, then we have that 
Before I start the proof for the theorem I recall what the definition of a Kneser graph is: It is a graph whose vertices corresponds to the -subset of an  -element set, and any two vertices are joint by an edge if and only the subsets are disjoint. It is usually denoted
-element set, and any two vertices are joint by an edge if and only the subsets are disjoint. It is usually denoted  . Here is an example for the case
. Here is an example for the case  :
:

Now the connection that the Kneser graph and the EKR theorem is the following: The collection is an independent set of the Kneser Graph because two vertices not sharing an edges means that the subsets intersect. Hence, the EKR can be stated as follows:
Theorem: The indepence number of (usually denoted  ) is less or equal to
) is less or equal to 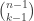 .
.
To prove this theorem the ingredients would be the following: We will find the eigenvalues and prove some bounds for  regular graphs, and then bound the size of an independent set. Then we will use this results in the Kneser graph.
regular graphs, and then bound the size of an independent set. Then we will use this results in the Kneser graph.
**************************************************************************
Say we are given a -regular graph  on vertices. If
on vertices. If  (This are the eigenvalues of the adjacency matrix
(This are the eigenvalues of the adjacency matrix  which is constructed by placing a
which is constructed by placing a  in the
in the  entry if and only if
entry if and only if  and a
and a  otherwise). Then for
otherwise). Then for  we have:
we have:

Proof:  . This is because is -regular so it works out nicely. Secondly, note that we can change the indice of summation for
. This is because is -regular so it works out nicely. Secondly, note that we can change the indice of summation for 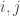 and add a
and add a  in the terms since this will be only when . Hence, we have:
in the terms since this will be only when . Hence, we have:


Now I am going to use a fact from linear algebra. If  is a symmetric matrix over the reals, then
is a symmetric matrix over the reals, then  . This implies that for any
. This implies that for any  we have that
we have that  . Then above
. Then above
 .
.
Hence, we proved that for any 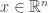 we have
we have  .
.
******************************************************************************
Now we will use this result to bound the independence number of a regular graph.
Theorem: is -regular with  eigenvalues. Then
eigenvalues. Then

Proof: Let  be any independent set. Then consider to be defined as follows:
be any independent set. Then consider to be defined as follows:

Now we just apply the above lemma to this case. We have:

since  will be if they are both in or if they are both in
will be if they are both in or if they are both in  , otherwise the difference will be . Then we note that the number of edges from to its complement is
, otherwise the difference will be . Then we note that the number of edges from to its complement is  since each vertex in is of degree and it doesnt connect to anything in that set, all the edges must go to the complement.
since each vertex in is of degree and it doesnt connect to anything in that set, all the edges must go to the complement.
Also, note that
![(d-\lambda_n)\sum_{i=1}^n x_i^2=(d-\lambda_n)[|I|(n-|I|)^2+(n-|I|)|I|^2]=(d-\lambda_n)(n-|I|)(|I|)n](https://s0.wp.com/latex.php?latex=%28d-%5Clambda_n%29%5Csum_%7Bi%3D1%7D%5En+x_i%5E2%3D%28d-%5Clambda_n%29%5B%7CI%7C%28n-%7CI%7C%29%5E2%2B%28n-%7CI%7C%29%7CI%7C%5E2%5D%3D%28d-%5Clambda_n%29%28n-%7CI%7C%29%28%7CI%7C%29n&bg=ffffff&fg=333333&s=0&c=20201002)
this is by splitting the sum into the two disjoint sets and . Hence, using the above lemma:

and when we solve to obtain  as we wanted.
as we wanted.
*************************************************************************************
Now time to solve the big theorem!
Proof: In our case we have that  is equal to
is equal to  . Also, note that the degree of all vertices is the same and it is equal to
. Also, note that the degree of all vertices is the same and it is equal to  (here we use the assumption that .
(here we use the assumption that .
Now using the fact that the smallest eigenvalue of is equal to  we get that
we get that

Just as we wanted to prove.
Note that the inequality is strict since to witness a family of -sets who all intersect take for instance all sets containing the fixed element . There are  elements left to pick and now each set needs
elements left to pick and now each set needs  to be complete for a total of .
to be complete for a total of .



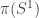
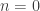




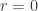
![[f_r]=[f_0]=[e_1]\in \pi(S^1)](https://s0.wp.com/latex.php?latex=%5Bf_r%5D%3D%5Bf_0%5D%3D%5Be_1%5D%5Cin+%5Cpi%28S%5E1%29&bg=ffffff&fg=333333&s=0&c=20201002)


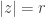





![[f_r]=n\cdot \omega](https://s0.wp.com/latex.php?latex=%5Bf_r%5D%3Dn%5Ccdot+%5Comega&bg=ffffff&fg=333333&s=0&c=20201002)
![[f_r]=0](https://s0.wp.com/latex.php?latex=%5Bf_r%5D%3D0&bg=ffffff&fg=333333&s=0&c=20201002)

 with the following property. Let
with the following property. Let  matrix with pairwise distinct entries. Then there is a permutation of the rows of
matrix with pairwise distinct entries. Then there is a permutation of the rows of 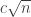 .
. be an arbitrary permutation of the rows. Then, let
be an arbitrary permutation of the rows. Then, let  be the event that some column has an increasing subsequence of length
be the event that some column has an increasing subsequence of length  later). Also, denote by
later). Also, denote by 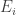 the event that column
the event that column  has an increasing subsequence of that length. Hence, we have that
has an increasing subsequence of that length. Hence, we have that  by symmetry. Now we calculate the probability that a fixed row will have a long subsequence using again the union bound. We can look at all possible subsequences of length
by symmetry. Now we calculate the probability that a fixed row will have a long subsequence using again the union bound. We can look at all possible subsequences of length 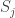 denote the event that the
denote the event that the  th subsequence is increasing (note that we have
th subsequence is increasing (note that we have  ), so
), so  because since the entries are pairwise distinct, then there is only one possible way that they will be in increasing order. Then,
because since the entries are pairwise distinct, then there is only one possible way that they will be in increasing order. Then,  . Putting everything together we get that:
. Putting everything together we get that:
 and
and  . Thus,
. Thus,
 , then we would have that
, then we would have that  which is clearly less than one and we are done. I will try to post more often!
which is clearly less than one and we are done. I will try to post more often! and
and  be two sets of family of families of an
be two sets of family of families of an 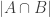 is odd for every
is odd for every  and every
and every  . Prove that
. Prove that  .
. and we will create two sets. We will double one of the sets and translate the other for a result of two orthogonal subspaces (they might not be subspaces but we use the term subspace to be understood as the subspace spanned by the set). Hence their dimensions sum up to
and we will create two sets. We will double one of the sets and translate the other for a result of two orthogonal subspaces (they might not be subspaces but we use the term subspace to be understood as the subspace spanned by the set). Hence their dimensions sum up to  and
and  be the set of incidency vectors of the sets in
be the set of incidency vectors of the sets in  be any element of
be any element of  . We claim that
. We claim that 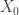 and
and 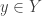 and a
and a  such that
such that  then we get a contradiction).
then we get a contradiction). (this is the doubling I meant on the sketch of the proof). Now since the dot product of
(this is the doubling I meant on the sketch of the proof). Now since the dot product of  and $y$ would be equal to
and $y$ would be equal to  . With this we have that for any
. With this we have that for any and
and  we have
we have  . Thus, we have that the sets
. Thus, we have that the sets  and
and 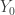 are orthogonal. Hence,
are orthogonal. Hence,
 such that if the integers
such that if the integers  are colored with
are colored with  in this set, having the same color, and satisfying:
in this set, having the same color, and satisfying: 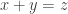
 was finite. Using this one can prove that the number
was finite. Using this one can prove that the number  is finite as well (here the number
is finite as well (here the number 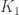 of color
of color 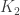 of color
of color  , and so on). The proof of this is by just checking that
, and so on). The proof of this is by just checking that  which is not difficult.
which is not difficult.  will work. Assume that we are given
will work. Assume that we are given 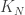 and label the vertices
and label the vertices  . Color the edges of the graph as follows: For the edge
. Color the edges of the graph as follows: For the edge  (wlog say
(wlog say  ) color it by the color received by
) color it by the color received by  in the set
in the set  . Hence we obtain a coloring of the graph
. Hence we obtain a coloring of the graph  (wlog say
(wlog say  ) such that they all have the same color. And here we have that
) such that they all have the same color. And here we have that  , so we are done.
, so we are done.  such that the distance between any two points is the same?.” The answer for this question is well known to be
such that the distance between any two points is the same?.” The answer for this question is well known to be  and the answer is given by a simplex. The generalization and content of this entry will be to answer the question: “What happens when we allow two distances?.”
and the answer is given by a simplex. The generalization and content of this entry will be to answer the question: “What happens when we allow two distances?.” and
and  be two distinct positive real numbrs. Let
be two distinct positive real numbrs. Let  denote the maximum number of points in
denote the maximum number of points in 
 vectors with exactly
vectors with exactly  of them in
of them in 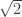 (the first is the case where none of their
(the first is the case where none of their  , so how do we get the extra
, so how do we get the extra 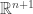 , using the same idea we can get
, using the same idea we can get  points in
points in  ), so we see that all of my points can actually be viewed as living in
), so we see that all of my points can actually be viewed as living in 
 be a set of points such that the distance between any two distinct
be a set of points such that the distance between any two distinct  and
and 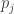 is either
is either 
 are linearly independent. Consider
are linearly independent. Consider
 . Note that if
. Note that if 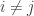 then
then  , but if
, but if  we have
we have  . Thus the above equation reads:
. Thus the above equation reads:
 and since this holds for every
and since this holds for every  ). This yields:
). This yields:

 . Then since
. Then since  we must have
we must have  is less or equal than this quantity. QED
is less or equal than this quantity. QED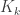 are “high”, so I have decided not to. If any of you have any suggestions on what you would like to see, you can email me.
are “high”, so I have decided not to. If any of you have any suggestions on what you would like to see, you can email me.![P[A]<1](https://s0.wp.com/latex.php?latex=P%5BA%5D%3C1&bg=ffffff&fg=333333&s=0&c=20201002) then with positive probability we must have
then with positive probability we must have ![P[A^c]>0](https://s0.wp.com/latex.php?latex=P%5BA%5Ec%5D%3E0&bg=ffffff&fg=333333&s=0&c=20201002) . The following will give an example of how this easy observation can be used to prove the existence of an event.
. The following will give an example of how this easy observation can be used to prove the existence of an event. ,
, .
. because there are
because there are  many edges and we want them to all be blue or all be red. Now we are going to do a very loose bound, the union bound. Recall from probability that
many edges and we want them to all be blue or all be red. Now we are going to do a very loose bound, the union bound. Recall from probability that![P[\bigcup A_i]\leq \sum_i P[A_i]](https://s0.wp.com/latex.php?latex=P%5B%5Cbigcup+A_i%5D%5Cleq+%5Csum_i+P%5BA_i%5D&bg=ffffff&fg=333333&s=0&c=20201002)
 many copies of
many copies of 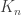 , we have that
, we have that![P[\text{ Some } K_k \text{ is monochromatic}]\leq \binom{n}{k}\frac{1}{2^{\binom{k}{2}}}\cdot 2](https://s0.wp.com/latex.php?latex=P%5B%5Ctext%7B+Some+%7D+K_k+%5Ctext%7B+is+monochromatic%7D%5D%5Cleq+%5Cbinom%7Bn%7D%7Bk%7D%5Cfrac%7B1%7D%7B2%5E%7B%5Cbinom%7Bk%7D%7B2%7D%7D%7D%5Ccdot+2&bg=ffffff&fg=333333&s=0&c=20201002)
 and we set
and we set  we have:
we have:
 , so in particular we have that
, so in particular we have that  , and thus we have proven a lower bound for the Ramsey number.
, and thus we have proven a lower bound for the Ramsey number. .
.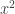 is congruent to either
is congruent to either  , then we have that
, then we have that  , but since its prime only
, but since its prime only  ).
). . Here
. Here  does not contain
does not contain 
 :
: if
if 
 if
if 
 if
if  .
. is an involution. Note however that it is a little cumbersome (but not hard) to check that
is an involution. Note however that it is a little cumbersome (but not hard) to check that  is an involution. Ill do one of the cases. Say
is an involution. Ill do one of the cases. Say  . Note now that (3) holds,
. Note now that (3) holds,  , so then we have
, so then we have  , and the reader can check that the other cases turn out to work out (I just thought of this, you should also verify that
, and the reader can check that the other cases turn out to work out (I just thought of this, you should also verify that  into itself, a priori it is not imediate that the image will also satisfy
into itself, a priori it is not imediate that the image will also satisfy  ), so indeed
), so indeed  be the finite set in question. If
be the finite set in question. If 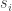 is not a fixed point then there exists an
is not a fixed point then there exists an 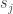 such that
such that  . Note that this forces
. Note that this forces  , so if we delete
, so if we delete 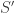 such that
such that  , in such a manner delete all the non-fixed points, so the result follows.
, in such a manner delete all the non-fixed points, so the result follows.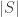 has odd parity, so the number of fixed points of
has odd parity, so the number of fixed points of  satisfying
satisfying  , and we would be done.
, and we would be done.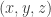 is a fixed point the it must be the case that it satisfies case
is a fixed point the it must be the case that it satisfies case 
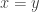 , since we have
, since we have  so
so  , and then
, and then  , so indeed
, so indeed 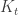 or a blue
or a blue 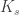 . Apriori this numbers are not finite (we could keep adding edges and coloring them either red or blue and always avoid a red
. Apriori this numbers are not finite (we could keep adding edges and coloring them either red or blue and always avoid a red  .
.
 , then assume that we are giving a coloring of
, then assume that we are giving a coloring of  be given. As the graph is complete, we have that
be given. As the graph is complete, we have that  . Either there are
. Either there are  red edges or
red edges or  blue edges. Without loss of generality, let us say that the first case holds. We have at least
blue edges. Without loss of generality, let us say that the first case holds. We have at least  red edges. Then consider a subgraph
red edges. Then consider a subgraph  that is formed by the
that is formed by the  -number of vertices adjacent to
-number of vertices adjacent to  in
in  . Note that if
. Note that if 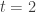 or
or  , then we have that
, then we have that  . And hence we would have that
. And hence we would have that
 with
with  .Then by our recursive looking bound we have that
.Then by our recursive looking bound we have that
 . To prove that in fact we have that
. To prove that in fact we have that  we have to exhibit a coloring of
we have to exhibit a coloring of 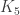 avoiding a monocolor red triangle and a monocolor blue triangle:
avoiding a monocolor red triangle and a monocolor blue triangle:
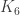 being colored red and blue we can prove the existence of a monocolor triangle directly using Pigeonhole’s Principle (in fact I have seen this problem given to students preparing for math olympiads).
being colored red and blue we can prove the existence of a monocolor triangle directly using Pigeonhole’s Principle (in fact I have seen this problem given to students preparing for math olympiads). . Imagine that we have
. Imagine that we have  ). Then consider
). Then consider  means that the first person driving in has
means that the first person driving in has  since this would mean that the first person got the third spot, the second person drove down to the third spot but since it was taken it had to drive out of the parking structure (and thus got fired). Let us denote by
since this would mean that the first person got the third spot, the second person drove down to the third spot but since it was taken it had to drive out of the parking structure (and thus got fired). Let us denote by  the number of parking functions on
the number of parking functions on 
 arrangements. Note that there will always be one spot empty after all cars have parked. By symmetry of the problem, the number of arrangements that have the
arrangements. Note that there will always be one spot empty after all cars have parked. By symmetry of the problem, the number of arrangements that have the  , note that these arrangements (the ones where the
, note that these arrangements (the ones where the 